Artificial Intelligence has been witnessing enormous enlargement in bridging the distance between the functions of people and machines. Researchers and fans indistinguishable, paintings on diverse facets of the grassland to put together superb issues occur. One such subject is the area of Computer Vision.
The schedule for this grassland is to allow machines to view the sector as people do, understand it in a matching way, or even importance the information for a large number of duties equivalent to Symbol & Video reputation, Symbol Research & Classification, Media Refreshment, Advice Techniques, Natural Language Processing, and so forth. The developments in Computer Vision with Deep Learning were built and perfected over months, essentially over one specific algorithm — a Convolutional Neural Network.
Advent
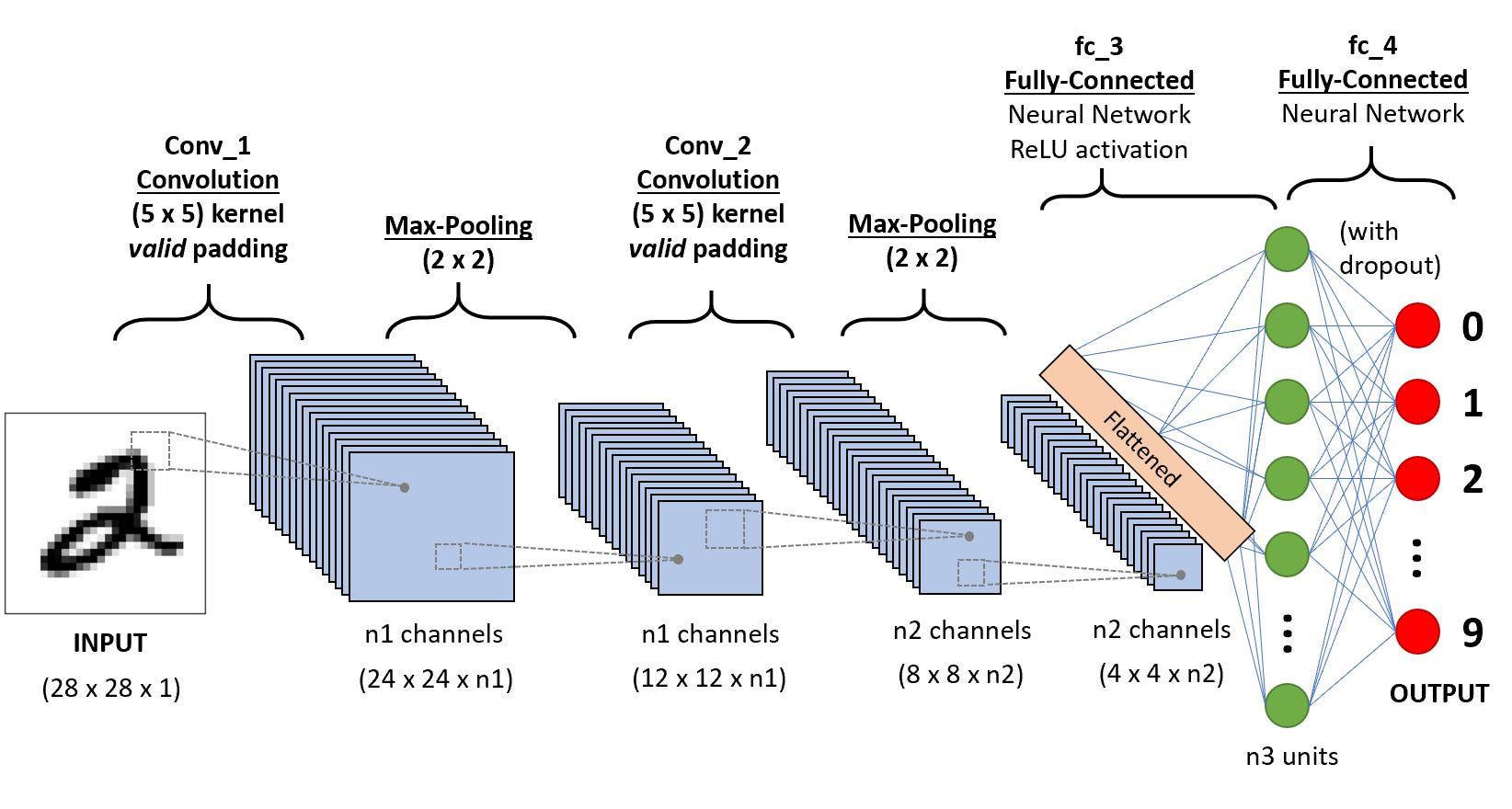
A CNN series to categorize handwritten digits
A Convolutional Neural Network (ConvNet/CNN) is a Deep Learning set of rules that may soak up an enter symbol, assign utility (learnable weights and biases) to numerous facets/gadgets within the symbol, and be capable of differentiating one from the alternative. The pre-processing required in a ConvNet is way decreased in comparison to alternative classification algorithms. Past in primitive forms filters are hand-engineered, with a plethora of coaching, ConvNets be capable of being told those filters/traits.
The structure of a ConvNet is comparable to that of the connectivity trend of Neurons within the Human Mind and was once impressed by way of the group of Sight Cortex. Person neurons reply to stimuli handiest in a limited patch of the optic grassland referred to as the Receptive Ground. A choice of such boxes overlaps to guard all the optic sections.
Why ConvNets over Feed-Ahead Neural Networks?
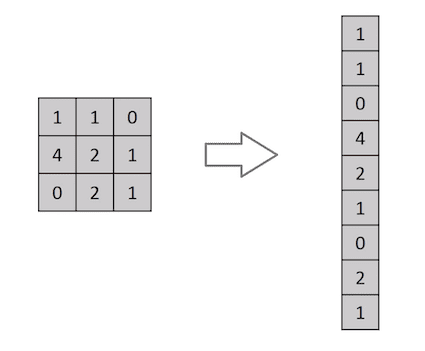
Knocking down a 3×3 symbol matrix right into a 9×1 vector
A picture is not anything; however, a matrix of pixel values, proper? So why now not simply flatten the picture (e.g., 3×3 symbol matrix right into a 9×1 vector) and feed it to a Multi-Stage Perceptron for classification functions? Uh.. now that is not true.
In circumstances of extraordinarily plain binary photographs, the mode may display a median precision rating date appearing prediction of categories. However, it would have slight to incorrect accuracy about advanced photographs having pixel dependencies all the way through.
A ConvNet is in a position to effectively seize the Spatial and Temporal dependencies in a picture during the utility of related filters. The structure plays a greater becoming in the picture dataset because of the aid within the choice of parameters and the weights’ reusability. In alternative phrases, the network may also be educated to grasp the sophistication of the picture higher.
Enter Symbol
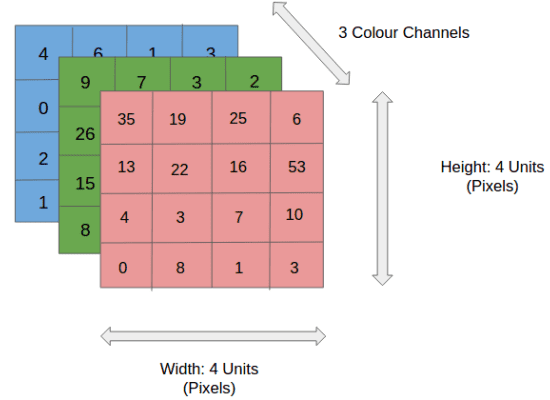
4x4x3 RGB Symbol
Within the determination, we have an RGB symbol separated by its three color planes — Purple, Inexperienced, and Blue. There are a variety of such color areas wherein photographs exist — Grayscale, RGB, HSV, CMYK, and so forth.
You’ll be able to consider how computationally extensive issues would get as soon as the photographs succeed in dimensions, say 8K (7680×4320). The function of ConvNet is to drop the photographs right into a method. This is more straightforward to the procedure without dropping options that are important for purchasing a just right prediction. That is notable once we are to design an structure that isn’t handiest just right at studying options but in addition scalable to immense datasets.
Convolution Layer — The Kernel
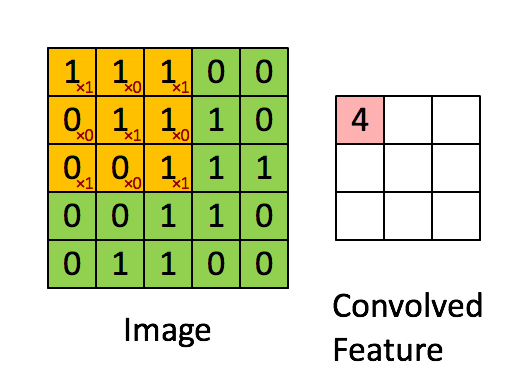
Convoluting a 5x5x1 symbol with a 3x3x1 kernel to get a 3x3x1 convolved component
Symbol Dimensions = 5 (Top) x 5 (Breadth) x 1 (Collection of channels, eg. RGB)
Within the above demonstration, the green golf division resembles our 5x5x1 enter symbol, I. The component concerned with the convolution operation within the first part of a Convolutional Layer is known as the Kernel/Clear out, Ok, represented in color yellow. Now we have decided on Ok as a 3x3x1 matrix.
Kernel/Clear out, Ok =
1 0 1
0 1 0
1 0 1The Kernel shifts nine occasions as a result of Stride Area = 1 (Non-Strided), each month appearing as an elementwise multiplication operation (Hadamard Product) between Ok and the portion P of the picture over which the kernel is soaring.
Motion of the Kernel
The filter out strikes to the suitable with an undeniable Stride Worth until it parses your complete width. Transferring on, it hops right down to the start (left) of the picture with the similar Stride Worth and repeats the method till all the symbol is traversed.
Convolution operation on an MxNx3 symbol matrix with a 3x3x3 Kernel
Concerning photographs with a couple of channels (e.g., RGB), the Kernel has the same intensity as that of the enter symbol. Matrix Multiplication is carried out between Kn and In stack ([K1, I1]; [K2, I2]; [K3, I3]), and the entire effects are summed with the partiality to offer us a squashed one-depth channel Convoluted Quality Output.
Convolution Operation with Stride Area = 2
The target of the Convolution Operation is to take out the high-level options equivalent to edges from the enter symbol. ConvNets needn’t be restricted to just one Convolutional Layer. Conventionally, the primary ConvLayer is accountable for taking pictures of the Low-Stage options equivalent to edges, color, gradient orientation, and so forth. With added layers, the structure adapts to the Top-Stage options as neatly, giving us a network that has a healthy working out of pictures within the dataset, matching how we’d.
There are two sorts of effects to the operation — one wherein the convolved component is lowered in dimensionality compared to the enter, and the other wherein the dimensionality is both larger or similar. That is carried out by way of making use of Legitimate Padding in terms of the previous or Similar Padding in terms of the ultimate.
Once we increase the 5x5x1 symbol right into a 6x6x1 symbol and next follow the 3x3x1 kernel over it, we discover that the convolved matrix seems to be of dimensions 5x5x1. Therefore the title — Similar Padding.
Alternatively, if we carry out a similar operation without padding, we’re introduced to a matrix with dimensions of the Kernel (3x3x1) itself — Legitimate Padding.
Refer to repository homes for many such GIFs, which might back up you get greater working out of ways Padding and Stride Area paintings in combination to succeed in effects related to our wishes.
[vdumoulin/conv_arithmetic]
A technical report on convolution arithmetic in the context of deep learning – Dumoulin/conv_arithmeticgithub.com](https://github.com/vdumoulin/conv_arithmetic)
Pooling Layer
Similar to the Convolutional Layer, the Pooling layer is accountable for decreasing the spatial measurement of the Convolved Quality. That is to trim the computational energy required to procedure the information thru dimensionality reduction. Moreover, it turns out to be useful for extracting dominant options that are rotational and positional invariant, thus keeping up the method of successfully coaching the type.
There are two sorts of Pooling: Max Pooling and Reasonable Pooling. Max Pooling returns the most worth from the portion of the picture lined by way of the Kernel. On the alternative hand, Reasonable Pooling returns the moderate of the entire values from the portion of the picture lined by way of the Kernel.
Max Pooling additionally plays as a Noise Suppressant. It discards the raucous activations altogether and likewise plays de-noising at the side of dimensionality aid. On the alternative hand, Reasonable Pooling merely plays a dimensionality aid as a noise-suppressing mechanism. Therefore, we will say that Max Pooling plays an accumulation higher than Reasonable Pooling.
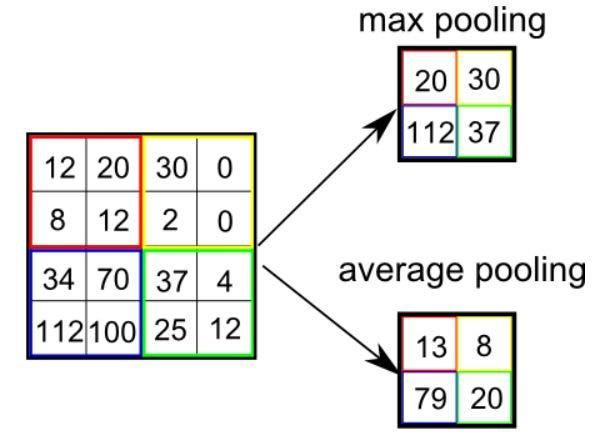
Forms of Pooling
The Convolutional Layer and the Pooling Layer, in combination method the i-th layer of a Convolutional Neural Network. Relying on the complexities within the photographs, the choice of such layers could also be wider for taking pictures of low-level main points, even additional, however, at the price of extra computational energy.
Later going through the above procedure, we effectively enabled the type to grasp the options. Transferring on, we’re going to flatten the overall output and feed it to an ordinary Neural Network for classification functions.
Classification — Attached Layer (FC Layer)
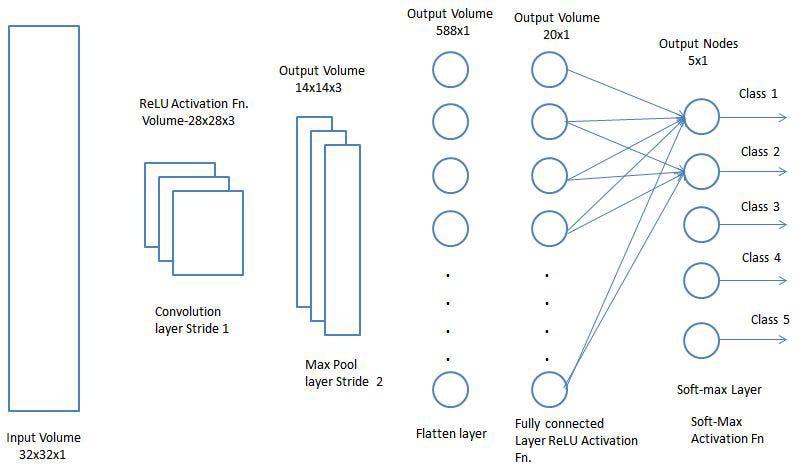
Including a Totally-Attached layer is a (generally) reasonable approach to studying non-linear combos of the high-level options as represented by way of the output of the convolutional layer. The Totally-Attached layer is studying a most likely non-linear serve in that field.
Now that we have transformed our enter symbol into an acceptable method for our Multi-Stage Perceptron, we will flatten the picture into a column vector. The flattened output is fed to a feed-forward Neural Network, and backpropagation is carried out for each iteration of coaching. Over a line of epochs, the type is in a position to distinguish between dominating and likely low-level options in photographs and classify them with the use of the Softmax Classification methodology.
There are numerous architectures of CNNs to be had that have been key in construction algorithms which energy and shall energy AI as a complete within the foreseeable generation. A few of them were indexed underneath:
- LeNet
- AlexNet
- VGGNet
- GoogLeNet
- ResNet
- ZFNet
Suggested article: 10 Practical Examples of AI Algorithms: Solving Real-World Problems